 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Static ISAC Assisted by Double-Side Fluid Antenna System
Apr 28, 2026As a pivotal usage scenario for 6G networks, integrated sensing and communication (ISAC) has emerged as a focal point of both academic and industrial research. To accommodate the heterogeneous connectivity requirements of future networks while jointly enhancing both the sensing and communication performance, this paper integrates the multi-static ISAC architecture with double-side fluid antenna system (DS-FAS) to fully exploit the available spatial degrees-of-freedom. Specifically, we establish a joint optimization framework for FA positions and transmit beamforming to maximize the target detection probability while satisfying the communication quality-of-service requirements. Recognizing the intricate coupling between the double-side FA positions and transmit beamforming, instead of trying to obtain an initial feasible point, we resort to the penalty-based mechanism to ensure the robustness against initial feasibility without introducing additional non-convexity. An alternating optimization-based algorithm is proposed to solve the decoupled subproblems. Specifically, the transmit beamforming is globally optimized via the semidefinite relaxation technique, while the transmit FA positions are determined using the majorization-minimization method. Finally, leveraging the analyzed FA mechanism, the feasibility subproblem for receive FA positions is transformed into a signal-to-interference-plus-noise ratio maximization one, solved efficiently via a gradient ascent-based approach, which yields superior performance over the feasibility-based benchmark with reduced complexity. Numerical results demonstrate the superiority of the considered DS-FAS-assisted multi-static ISAC systems in both noise-limited and interference-limited scenarios, while key insights for practical deployment are further extracted from the simulation analysis.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
WenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
Semantic-VAE: Semantic-Alignment Latent Representation for Better Speech Synthesis
Sep 26, 2025While mel-spectrograms have been widely utilized as intermediate representations in zero-shot text-to-speech (TTS), their inherent redundancy leads to inefficiency in learning text-speech alignment. Compact VAE-based latent representations have recently emerged as a stronger alternative, but they also face a fundamental optimization dilemma: higher-dimensional latent spaces improve reconstruction quality and speaker similarity, but degrade intelligibility, while lower-dimensional spaces improve intelligibility at the expense of reconstruction fidelity. To overcome this dilemma, we propose Semantic-VAE, a novel VAE framework that utilizes semantic alignment regularization in the latent space. This design alleviates the reconstruction-generation trade-off by capturing semantic structure in high-dimensional latent representations. Extensive experiments demonstrate that Semantic-VAE significantly improves synthesis quality and training efficiency. When integrated into F5-TTS, our method achieves 2.10% WER and 0.64 speaker similarity on LibriSpeech-PC, outperforming mel-based systems (2.23%, 0.60) and vanilla acoustic VAE baselines (2.65%, 0.59). We also release the code and models to facilitate further research.
REF-VC: Robust, Expressive and Fast Zero-Shot Voice Conversion with Diffusion Transformers
Aug 07, 2025In real-world voice conversion applications, environmental noise in source speech and user demands for expressive output pose critical challenges. Traditional ASR-based methods ensure noise robustness but suppress prosody, while SSL-based models improve expressiveness but suffer from timbre leakage and noise sensitivity. This paper proposes REF-VC, a noise-robust expressive voice conversion system. Key innovations include: (1) A random erasing strategy to mitigate the information redundancy inherent in SSL feature, enhancing noise robustness and expressiveness; (2) Implicit alignment inspired by E2TTS to suppress non-essential feature reconstruction; (3) Integration of Shortcut Models to accelerate flow matching inference, significantly reducing to 4 steps. Experimental results demonstrate that our model outperforms baselines such as Seed-VC in zero-shot scenarios on the noisy set, while also performing comparably to Seed-VC on the clean set. In addition, REF-VC can be compatible with singing voice conversion within one model.
Finite-Precision Conjugate Gradient Method for Massive MIMO Detection
Apr 14, 2025The implementation of the conjugate gradient (CG) method for massive MIMO detection is computationally challenging, especially for a large number of users and correlated channels. In this paper, we propose a low computational complexity CG detection from a finite-precision perspective. First, we develop a finite-precision CG (FP-CG) detection to mitigate the computational bottleneck of each CG iteration and provide the attainable accuracy, convergence, and computational complexity analysis to reveal the impact of finite-precision arithmetic. A practical heuristic is presented to select suitable precisions. Then, to further reduce the number of iterations, we propose a joint finite-precision and block-Jacobi preconditioned CG (FP-BJ-CG) detection. The corresponding performance analysis is also provided. Finally, simulation results validate the theoretical insights and demonstrate the superiority of the proposed detection.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025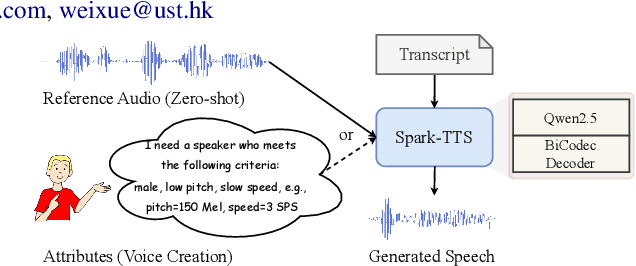



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Performance Analysis of Local Partial MMSE Precoding Based User-Centric Cell-Free Massive MIMO Systems and Deployment Optimization
Oct 08, 2024



Cell-free massive multiple-input multiple-output (MIMO) systems, leveraging tight cooperation among wireless access points, exhibit remarkable signal enhancement and interference suppression capabilities, demonstrating significant performance advantages over traditional cellular networks. This paper investigates the performance and deployment optimization of a user-centric scalable cell-free massive MIMO system with imperfect channel information over correlated Rayleigh fading channels. Based on the large-dimensional random matrix theory, this paper presents the deterministic equivalent of the ergodic sum rate for this system when applying the local partial minimum mean square error (LP-MMSE) precoding method, along with its derivative with respect to the channel correlation matrix. Furthermore, utilizing the derivative of the ergodic sum rate, this paper designs a Barzilai-Borwein based gradient descent method to improve system deployment. Simulation experiments demonstrate that under various parameter settings and large-scale antenna configurations, the deterministic equivalent of the ergodic sum rate accurately approximates the Monte Carlo ergodic sum rate of the system. Furthermore, the deployment optimization algorithm effectively enhances the ergodic sum rate of this system by optimizing the positions of access points.
M-Vec: Matryoshka Speaker Embeddings with Flexible Dimensions
Sep 24, 2024



Fixed-dimensional speaker embeddings have become the dominant approach in speaker modeling, typically spanning hundreds to thousands of dimensions. These dimensions are hyperparameters that are not specifically picked, nor are they hierarchically ordered in terms of importance. In large-scale speaker representation databases, reducing the dimensionality of embeddings can significantly lower storage and computational costs. However, directly training low-dimensional representations often yields suboptimal performance. In this paper, we introduce the Matryoshka speaker embedding, a method that allows dynamic extraction of sub-dimensions from the embedding while maintaining performance. Our approach is validated on the VoxCeleb dataset, demonstrating that it can achieve extremely low-dimensional embeddings, such as 8 dimensions, while preserving high speaker verification performance.